

Introduction
As software systems become increasingly complex and interconnected, ensuring their reliability in the face of unexpected failures has become a top priority for engineering teams. One effective approach to testing resilience is chaos engineering, which involves intentionally introducing controlled failures into a system to determine its ability to withstand real-world scenarios.
What is Chaos Engineering?
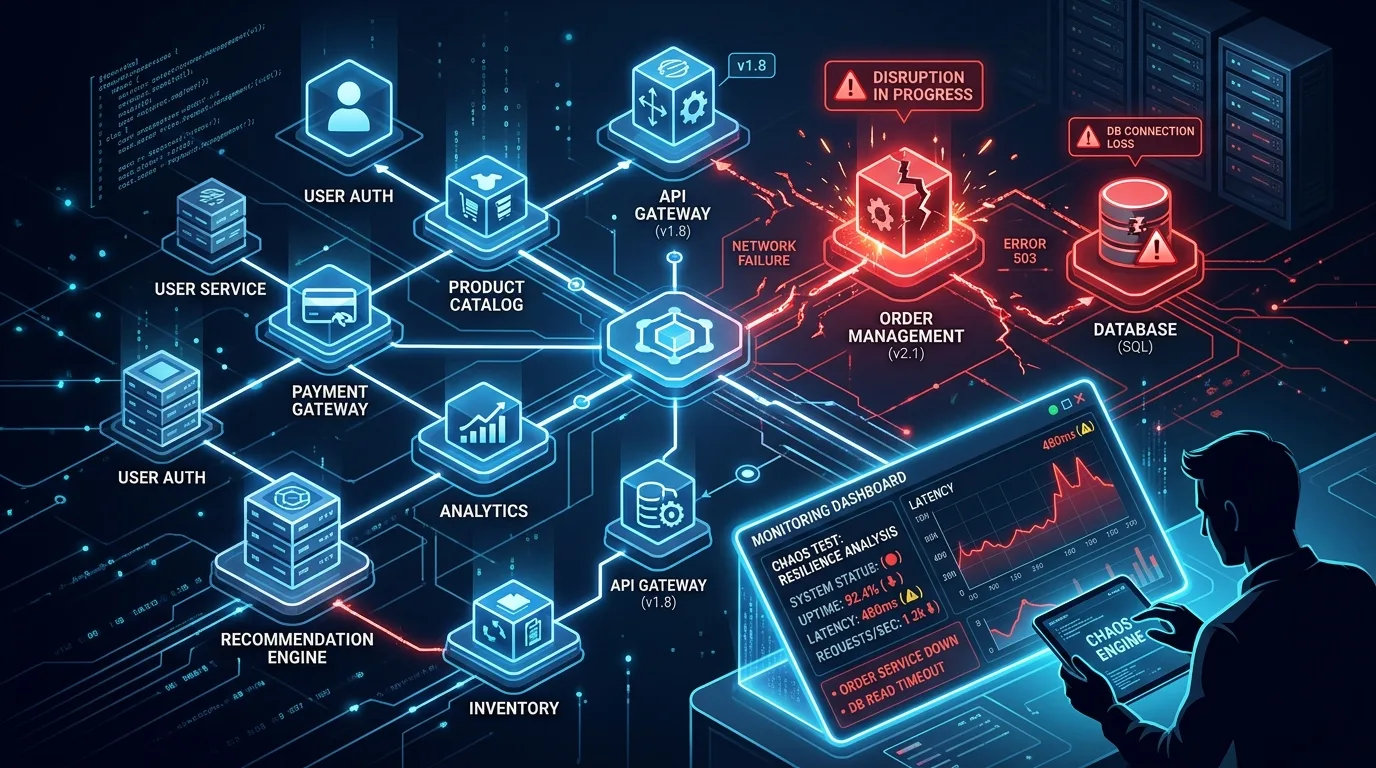
Chaos engineering is a software development practice that involves intentionally introducing failures or stress into a system to evaluate its behavior under real-world scenarios. This approach helps identify vulnerabilities, optimize resource utilization, and ensure the overall reliability of a system. By simulating potential failures, teams can proactively address issues before they impact end-users.
Key Benefits of Chaos Engineering
Chaos engineering offers several key benefits, including:
Improved reliability: Identifying potential failure points enables teams to develop strategies for mitigating risks.
Enhanced fault tolerance: Systems are designed to recover from unexpected failures, reducing downtime and improving overall performance.
Resource optimization: Chaos engineering helps identify areas where resources can be optimized, leading to cost savings.
What is Gremlin?
Gremlin is a popular chaos engineering tool that enables teams to simulate real-world scenarios, such as network outages, database crashes, or service interruptions. By injecting controlled failures into the system, Gremlin helps teams:
Identify bottlenecks: Simulate resource-intensive tasks to identify performance bottlenecks.
Test recovery mechanisms: Evaluate a system's ability to recover from unexpected failures.
Optimize resource utilization: Reduce waste and improve efficiency by identifying areas for optimization.
Implementing Gremlin
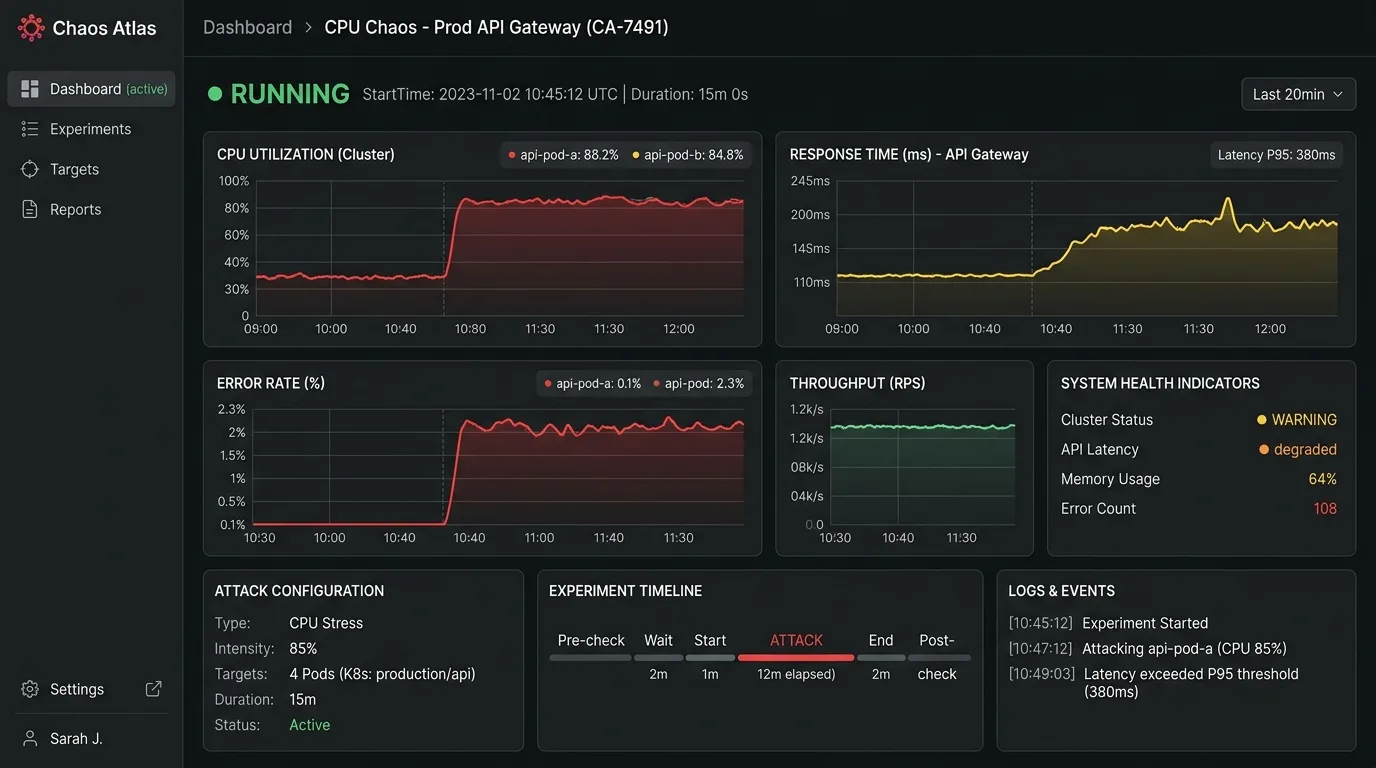
Implementing Gremlin involves the following steps:
1. Define experiment scope: Identify specific components or services to target with chaos engineering experiments. + Consider the system's architecture, dependencies, and potential failure points when defining the experiment scope.
2. Configure Gremlin: Set up and configure Gremlin to simulate desired failure scenarios. + Ensure that Gremlin is properly integrated with the system under test, including any necessary authentication or authorization mechanisms. 3. Run experiments: Execute chaos engineering experiments, monitoring system behavior and response. + Use tools like monitoring software, logging, and alerting systems to track system performance during experiments.
4. Analyze results: Review data collected during experiments to identify areas for improvement. + Use metrics such as error rates, latency, and resource utilization to inform optimization efforts.
Best Practices for Using Chaos Engineering Tools
While implementing chaos engineering with tools like Gremlin can be beneficial, it's essential to follow best practices to ensure successful outcomes:
Start small: Begin with simple experiments and gradually increase complexity.
+ This approach allows teams to refine their testing strategy, avoid overwhelming the system under test, and minimize potential disruptions.
Communicate effectively: Inform stakeholders about the purpose and scope of chaos engineering experiments.
+ Clearly explain the goals and objectives of chaos engineering experiments, including any expected outcomes or risks.
Monitor and analyze results: Carefully review data collected during experiments to identify areas for improvement.
+ Use insights gained from chaos engineering experiments to inform future optimization efforts.
Addressing Reader Pain Points
Many teams struggle with testing resilience in microservices, often due to:
1. Difficulty in identifying potential failure points: Chaos engineering helps identify vulnerabilities before they impact end-users.
2. Need for faster deployment speed: By proactively addressing issues through chaos engineering, teams can accelerate deployment cycles.
Case Study: Implementing Chaos Engineering with Gremlin
One example of successful implementation comes from a major e-commerce company that used Gremlin to improve the reliability of their payment processing system. By simulating network outages and database crashes, the team identified vulnerabilities in their architecture and optimized resource utilization.
Benefits of Implementation
As a result of implementing chaos engineering with Gremlin, the e-commerce company achieved:
Improved transaction throughput: Reduced failure rates by 30% through optimized resource allocation.
Enhanced customer satisfaction: Decreased downtime and improved overall performance.
Conclusion
Implementing chaos engineering with tools like Gremlin can significantly enhance system reliability and improve deployment speed. By understanding the concept of chaos engineering, its benefits, and best practices for implementation, teams can proactively address potential failure points and ensure their systems remain resilient in the face of unexpected failures.
Future Directions
As chaos engineering continues to evolve as a practice, there are several areas worth exploring:
Integration with DevOps pipelines: Chaos engineering can be integrated into existing DevOps workflows, enabling continuous monitoring and optimization.
Real-world scenario simulation: Tools like Gremlin can simulate real-world scenarios, such as network outages or database crashes, to test system resilience.
Compliance and regulatory requirements: Chaos engineering can help ensure compliance with industry standards and regulatory requirements.
Best Practices for Incorporating Chaos Engineering into Existing DevOps Pipelines
To incorporate chaos engineering into existing DevOps pipelines, teams should:
1. Define experiment scope: Identify specific components or services to target with chaos engineering experiments. 2. Configure Gremlin: Set up and configure Gremlin to simulate desired failure scenarios.
3. Run experiments: Execute chaos engineering experiments, monitoring system behavior and response.
4. Analyze results: Review data collected during experiments to identify areas for improvement.
Conclusion
In conclusion, chaos engineering is a powerful practice that can enhance system reliability and improve deployment speed. By understanding the benefits of chaos engineering and implementing tools like Gremlin, teams can proactively address potential failure points and ensure their systems remain resilient in the face of unexpected failures.
This Article was made with AI assistance and human editing.